

- Введение в xml¶
- В заключение описания процесса
- Указанный вами ключ принадлежит бин …, что не соответствует бин, указанному в профиле
- 2. Описание трансформации
- Первичный импорт.
- 1. Получение таблички со структурой документов.
- 1. Пивотирование
- Re: ключи импорт ключей взятые с цона, а так же изменение па
- Well formed xml
- Значение элемента
- Какое заявление необходимо заполнить для обновления ключа соно? (а. дорохова, 11 августа 2021 г.)
- Ключи импорт ключей взятые с цона, а так же изменение пароля : ис соно система обработки налоговой отчетности
- Конструктивный форум бухгалтеров казахстана • просмотр темы – переход на «новые ключи нуц» со «старых ключей кн»
- Подготовка подписи к долгосрочному хранению
- Поиск информации в xml файлах (xpath)¶
- Практика: составляем свой запрос
- Проверка подписи на стороне сервера
- Программа “загрузка xml для соно” [для ожидает загрузки xml] : ис соно система обработки налоговой отчетности
- Сущности¶
- Указанный вами ключ поврежден или не соответствует требуемому алгоритму шифрования для юл
- Шаг 2. установка соно и настройка сертификатов соно.
- Шаг 3. загрузка шаблонов фно в соно нп.
- Итого
Введение в xml¶
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки,
предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа <book> (открывающий тег).
Следующие 4 строки описывают дочерние элементы корневого элемента ( title, author, year, price).
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Информация, заключенная между тегами, называется содержимым или значением элемента: <author>ErikT.Ray</author>. Т.е. элемент author принимает значение ErikT.Ray. Элементы могут вообще не принимать значения.
Элементы могут содержать атрибуты, так, например, открывающий тег <titlelang=”en”> имеет атрибут lang, который принимает значение en. Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ / ставится в конце открывающего тега:
В заключение описания процесса
Иерархический идентификатор в каждой целевой таблице дает нам возможность связать эти таблицы друг с другом (причем в любом порядке, при необходимости можно опускать промежуточные звенья). Как отмечалось выше, фиксированный размер элементов иерархического идентификатора дает нам возможность достаточно легко строить выражения для связывания наших целевых таблиц.
Конечно же, при желании можно дополнить структуру таблиц связями через значения привычных автоинкрементных ключей.
Отметим достаточную толерантность описанного подхода к ошибкам и упущениям разработчика (точнее, человека, конфигурирующего маппинг). Если в процессе подготовки трансформации вы упустили нужное поле, или если в схеме файлов произошли изменения типа добавления или переименования полей, которые не были отслежены вовремя – ничего страшного, даже если большой объем информации уже обработан без учета этой ошибки.
Вся информация у нас сохранена и доступна в нашем “первичном” табличном хранилище, поэтому заново парсить исходники не придется.
Можно прописать маппинг полей для «маленькой» трансформации данных – только для нужного нам пропущенного фрагмента. После того как мы “вытащим” недостающий кусок данных, мы сможем достаточно легко “подцепить” его к основному обработанному массиву через связку по иерархическому идентификатору.
Указанный вами ключ принадлежит бин …, что не соответствует бин, указанному в профиле
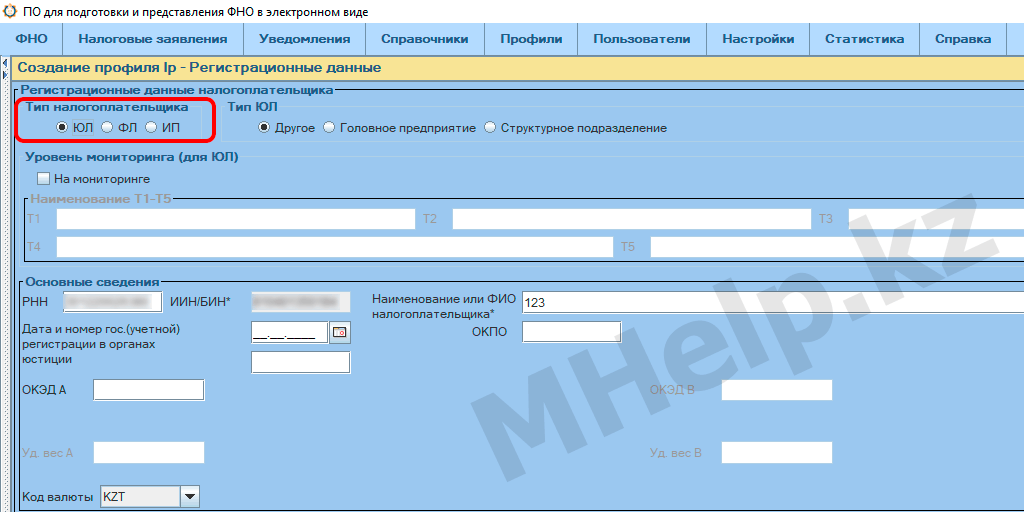
Ошибка возникает при попытке подключить ключ ЭЦП другого Юридического лица (ЮЛ) или при неверном указании Тип налогоплательщика в профиле СОНО.
Убедитесь, что вы указываете ключ GOSTKNCA действительной организации указанной в профиле.
А так же, что в поле Тип налогоплательщика (верхняя часть окна профиля СОНО) указано — ЮЛ.
2. Описание трансформации
Получив исходные данные в виде табличной спецификации документов, переходим к дизайну трансформации данных. В результате этой трансформации мы преобразуем данные нашего исходного хранилища первичного XML в новые таблицы с новыми именами полей и уникальными кодами записей целевых таблиц. Нам не нужны какие-то специальные программные инструменты, просто добавим к этой табличке несколько новых столбцов:
Вот какие поля мы добавили:
- Имя целевой таблицы TargetTable. Обратите внимание, что мы учитываем информацию о размножении один-ко-многим (столбец maxoccurs) для определения, в какую таблицу какие данные заливать.
- Имя поля целевой таблицы TargetField. Мы далее используем подход сonvention over configuration и будем присваивать суффикс _Dim для полей, которые станут справочниками-измерениями (dimensions), суффикс _Date для полей дат и суффикс _Val для числовых полей- мер (measures). На следующих этапах процесса соответствующие утилиты по суффиксу поймут что делать с данным полем – строить и обновлять нужный справочник или преобразовывать значение в соответствующий формат.
- Эффективная глубина вложенности элементов ElementDepth. Нам надо будет для последующих трансформаций сохранить единый код записи целевой таблицы на базе содержимого полей Record_ID и File_ID. В XML глубина элементов может быть разной, но попадать они должны будут в одну целевую таблицу, поэтому мы указываем, какую часть иерархического кода Record_ID нам надо сохранить, отбросив ненужный нам остаток. Благодаря фиксированной длине каждого сегмента иерархического кода, это будет достаточно “дешевая” операция выделения подстрок длины [Количество символов на сегмент кода]* ElementDepth.
- Дополнительная информация AdditionalInfo. В результате нашей трансформации мы перегрузим исходные данные в разбивке по целевым таблицам в похожую структуру с новыми названиями полей, однако в некоторых местах нам надо будет сохранить важную информацию о том, из какого именно XPATH-пути мы брали исходные данные.
Эта техника открывает несколько интересных возможностей манипуляции трансформацией данных. Не углубляясь в детали, просто перечислим что мы можем сделать:
После того, как наша табличка со спецификацией трансформации готова, мы загружаем ее в базу данных и джойним с нашим первичным хранилищем по полям
PathElement_Name
Конкатенацией File_ID, “обрезанного” в соответствии с ElementDepth значения поля Record_ID и значения AdditionalInfo формируем композитный ключ нашей целевой таблицы.
Результат джойна выливаем для каждой целевой таблицы в отдельную “временную” таблицу (в зависимости от объема данных можно попробовать использовать результат запроса “ на лету ”), на следующем этапе с этими таблицами будут работать завершающие утилиты нашего “конвейера”.
- До выливки мы имеем набор данных на уровне отдельных полей (элементов). Для того, чтобы соединить поля в записи результирующей таблицы, нам нужно иметь какой-то ключ, который будет однозначно идентифицировать запись целевой таблицы, в которую попадут соответствующие поля.
- Иерархический идентификатор Record_ID может быть разной длины, в зависимости от “глубины залегания” отдельных элементов в схеме документа. Однако, если углубление уровня не сопровождается размножением элементов один-ко-многим, мы обрезаем наш Record_ID до минимальной достаточной глубины, определенной параметром ElementDepth, что обеспечит нам одинаковость идентификатора для всех полей нашей целевой таблицы. В наших демо-документах такой ситуации нет, но представьте, к примеру, что наш UnitPrice “разветвлялся” бы на 2 значения – оптовую и розничную цены UnitPriceRetail и UnitPriceWholesale.
- Поскольку в нашем базовом хранилище лежит содержимое множества файлов, в нашем ключе без значения File_ID не обойтись.
- Следующие этапы преобразования данных работают только с полученными на данном шаге “трансформированными” таблицами, никакой сквозной системы настроек у нас нет. Тип поля (dimension/measure) мы передаем через суффиксы названий, но иногда нам надо передать “по цепочке” еще и информацию о том, в каком именно разделе документа мы брали информацию (помним, что мы можем трансформировать в одинаковый вид документы, закодированные разными схемами). Для передачи на следующий этап преобразования этой информации мы используем необязательный параметр нашей трансформации AdditionalInfo, “подцепив” его к нашему композитному ключу так, чтобы не нарушилась нужная нам идентификация целевых записей.
Посмотрим, что получилось на выходе в нашем примере:
Обратите внимание – полученный ключ одинаков для всех полей, которые войдут в соответствующие записи наших целевых таблиц.
Первичный импорт.
Мы рассматриваем XML-документ как дерево, вершинами которого являются пары “имя”-“значение”. Таким образом, описываемый подход достаточно универсален и может быть применен к любому древовидному представлению данных.
Структура таблицы для загрузки данных из XML:
Идея загрузки дерева в таблицу достаточно очевидная. В MS SQL (про другие СУБД не скажу, не смотрел) есть такая встроенная возможность –XML без указания схемы импортируется в так называемую EDGE-таблицу. Это не совсем то что нам нужно, т. к. в EDGE-формате хранятся отдельными записями имя элемента и его значение (то есть имя есть родительская запись для значения) – такой формат попросту неудобно использовать для дальнейших манипуляций. К тому же в EDGE таблице связи в дереве прописаны через указание ParentID.
Короче говоря, сделать нужное представление данных из EDGE таблицы можно, но придется немножко попотеть для “склеивания” названий и значений элементов, воссоздания XPATH до каждого элемента и создания иерархического идентификатора (о том, как мы его будем строить – чуть ниже).
Более правильный путь – получить дерево документа с помощью XML-парсера (какая-нибудь реализация есть практически в каждом языке и среде разработки) и заполнить нужную информацию одним проходом по документу.
Давайте посмотрим на конкретный пример. Есть у нас демо XML-файлы deliveries.xml и returns.xml. Файл deliveries.xml (доставки) содержит корневой элемент Deliveries, на верхнем уровне даты начала и окончания периода за который выгружены данные, дальше идут продукты с указанием названия и поставщика, по каждому продукту идет детализация информации доставок – дата, количество, цена.
Файл
returns.xml (возвраты)
абсолютно аналогичный, только корневой элемент называется Returns и в деталях элемент с датой по-другому называется.
Имена загруженных файлов хранятся в отдельной таблице, коды наших файлов там равны 2006 (deliveries) и 2007 (returns).
В нашей таблице-приемнике образ наших демо-документов будет выглядеть так:
По поводу иерархического идентификатора
Record_ID
: его цель — уникально пронумеровать узлы дерева документа с сохранением информации о связях со всеми предками.
В приведенном примере мы используем простую платформенно-независимую реализацию c последовательной конкатенацией счетчиков элементов на каждом уровне дерева. Мы “добиваем” счетчик каждого уровня нулями до заданной фиксированной глубины, чтобы получить легкое и быстрое выделение идентификаторов предков любого уровня через выделение подстрок фиксированной длины.
Вот собственно и все на этом этапе. Теперь мы можем простыми SQL-запросами выделить подмножества данных продуктов, деталей по доставкам или возвратам и связать их друг с другом через идентификаторы файлов и элементов.
Во многих случаях этого подхода будет вполне достаточно для эффективного хранения данных и организации доступа к ним, описанные далее “продвинутые” техники могут не понадобиться.
Действительно, мы уже загрузили все наши данные в единое хранилище, не обращая внимания на возможную разницу в структуре документов, получили достаточно эффективный способ вычленять нужную информацию из всего массива простыми SQL-запросами, можем связывать между собой “вычлененные” подмножества данных.
Производительность такого решения как системы хранения исходников XML для разовых запросов, даже без оптимизации индексов и прочих ухищрений, будет явно гораздо выше, чем если бы вы хранили XML в файлах или даже записывали его в специальные поля БД. В нашем случае не надо запускать процедуру XPATH поиска (которая подразумевает новый парсинг) к каждому документу, мы это проделали один раз и дальше спокойно пользуемся сохраненным результатом через достаточно простые запросы.
На следующих этапах мы рассмотрим трансформацию этих XML документов в единую структуру данных, содержащую 3 таблицы:
MovementReports
(тип движения – доставка или возврат, даты начала и окончания из корня документа),
Products
(название и поставщик) и
MovementDetails
(цена, количество, дата – поле даты в результате будет единое для обоих исходных документов, несмотря на то, что в исходных файлах поля по-разному называются)
1. Получение таблички со структурой документов.
Для дальнейшей обработки нужно иметь развернутую структуру всех наших XML-документов, чтобы на ее основе решать в какую структуру таблиц мы все это будем преобразовать.
Одного конкретного образца XML-документа для этой задачи нам мало, в конкретном документе может не быть каких-то необязательных элементов, которые неожиданно обнаружатся в других документах.
Если у нас нет XSD-схемы или мы не хотим с ней связываться, то нам может быть достаточно загрузить в нашу таблицу какую-то репрезентативную выборку образцов XML-документов и построить с помощью группировки по полям Path и Element_Name нужный нам список.
Однако не забывайте, что мы хотим в итоге загрузить информацию в некие целевые “финальные” таблицы, поэтому нам надо знать где в XML хранятся отношения один-ко-многим. То есть надо понять какие элементы формируют “дочернюю” таблицу, где происходит размножение.
Иногда, если схема документа не очень сложная, нам это сразу понятно эмпирически, “глазками”. Также при группировке данных нашей “репрезентативной выборки” мы можем посчитать количество элементов и увидеть по этой статистике где они начинают “размножаться”.
Как видим, задача немного усложняется: хочется получить не только простую табличку, содержащую список XPATH-путей для всех элементов наших документов, но еще и с указанием того, где начинается размножение данных. (А при анализе хорошо прописанной XSD-схемы приятном бонусом могли бы получить возможность вытащить описания элементов и их типы.)
Очень хорошо было бы для получения такой таблички использовать функциональность какого-нибудь XML-редактора, однако найти такой инструмент, который бы выдавал нужную нам структуру документов по XSD-схеме, не удалось (искали и пробовали долго).
Во всех этих Oxygen, Altova, Liquid и менее навороченных нужная информация внутри, несомненно, используется – однако отдавать ее в нужном виде никто из них не умеет. Как правило, в продвинутом редакторе есть возможность генерировать Sample XML на основании схемы, но в XSD может быть конструкция choice, когда в документе может присутствовать что-то на выбор из нескольких разных элементов –тогда уж лучше реальные “боевые” образцы документов проанализировать. И еще — по образцу или образцам документов мы момент размножения информации один-ко-многим в явном виде тоже не поймаем.
В итоге пришлось изобретать велосипед и писать генератор такой таблички (фактически, парсер XSD специального вида) самостоятельно. Благо XSD это тоже XML, его можно так же загрузить в наше хранилище и реляционными операциями вытащить нужный вид. Если схема простая, без ссылок на сложные типы элементов и без наследования от базовых типов, то это достаточно просто. В случае, когда все это наследование типов в наличии (как в госзакупках, например), задача посложнее.
1. Пивотирование
Получив в результате предыдущей трансформации “заготовку” целевой таблицы с исходными данными, разбитыми на тройки
, мы должны перевести ее в более привычный вид таблицы со множеством полей. Алгоритм этого преобразования очевиден – сначала группировкой значений нашего композитного ключа получаем “скелет” таблицы, потом осуществляем джойны этого “скелета” с таблицей-результатом трансформации по значению композитного ключа. (“Наращиваем мясо”, так сказать.)
То есть получится N соединений “скелета” с подмножествами таблицы- результата трансформации, выделенными по именам полей, где N- количество названий полей в целевой таблице-результате трансформации.
Мы благополучно “донесли” поле AdditionalInfo до данной стадии, закодировав его внутри композитного ключа. Теперь надо освободить наш ключ от этой “обузы” и отрезать AdditionalInfo-часть в новое поле AdditionalInfo_Dim.
Мы соединяли код файла и идентификатор записи, чтобы передать на этап пивотирования ключ одним полем. Для “финального” хранения лучше обратно разделить код файла и иерархический идентификатор на два поля, так будет проще связывать результирующие таблицы друг с другом.
В итоге получатся такие вот
Re: ключи импорт ключей взятые с цона, а так же изменение па
Кайрат-F2» 20 фев 2021, 18:23
- Похожие темы Ответы Просмотры Последнее сообщение
- Работа с ключами НУЦ (с ЦОНа) в налоговых программах.
1 , 2 , 3 , 4
GRaiS » 14 фев 2021, 16:34 63 Ответы 23478 Просмотры Последнее сообщение Necytij
10 ноя 2021, 14:45 - Ключи для СОНО.
1 , 2 , 3
pavel1680 » 29 апр 2009, 12:12 55 Ответы 7421 Просмотры Последнее сообщение Кайрат-F2
12 авг 2021, 17:11 - Ключи ЦОН с сайта pki.gov.kz можно ли использовать в СОНО?
repoy » 01 май 2021, 16:34 4 Ответы 22948 Просмотры Последнее сообщение Кайрат-F2
09 июл 2021, 13:34 - Программа Импорт формы Декларации 300.00 в СОНО
1 . 12 , 13 , 14
sokref » 13 май 2009, 12:04 266 Ответы 28138 Просмотры Последнее сообщение Кайрат-F2
11 ноя 2021, 18:10 - Программа Импорт формы Декларации 300.00 в СОНО (от 15.05.09
1 , 2 , 3 , 4 , 5
Lada » 15 май 2009, 16:14 80 Ответы 5140 Просмотры Последнее сообщение Lada
29 июл 2009, 18:00
Well formed xml
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
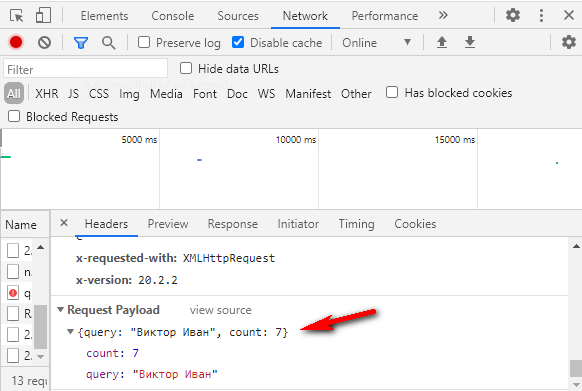
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.
См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
Обратите внимание:
Но оба значения идут
без
кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Какое заявление необходимо заполнить для обновления ключа соно? (а. дорохова, 11 августа 2021 г.)
А. Дорохова, CAP, ДипИФР,
профессиональный бухгалтер РК
КАКОЕ ЗАЯВЛЕНИЕ НЕОБХОДИМО ЗАПОЛНИТЬ ДЛЯ ОБНОВЛЕНИЯ КЛЮЧА СОНО?
Какой формы должно быть написано заявление для обновления ключа СОНО, если кончился срок действия?
Положения Налогового кодекса. Электронный налогоплательщик – налогоплательщик, взаимодействующий с органами налоговой службы электронным способом на основе заключенного с органами налоговой службы соглашения об использовании и признании электронной цифровой подписи при обмене электронными документами в порядке, установленном Налоговым кодексом.
Электронная цифровая подпись налогоплательщика – это последовательность электронных цифровых символов, созданная средствами электронной цифровой подписи и подтверждающая достоверность электронного документа, его принадлежность налогоплательщику и неизменность содержания.
Для постановки на регистрационный учет в качестве электронного налогоплательщика налогоплательщик в явочном порядке представляет налоговое заявление о регистрационном учете электронного налогоплательщика, утвержденное постановлением Правительства РК от 29 ноября 2021 года № 1390 (Приложение 17) в налоговый орган по месту нахождения или жительства налогоплательщика. Данное заявление можно скачать на официальном сайте Налогового комитета Министерства финансов по ссылке: http://www.salyk.ecpexpert.ru/ru/taxcode/Npa/Pages/nalogzayavlenia.aspx.
Налогоплательщик вправе представить налоговое заявление о регистрационном учете электронного налогоплательщика для аннулирования электронной цифровой подписи или ее замены в налоговый орган по месту нахождения или жительства в случаях:
– принятия решения об отказе от использования электронной цифровой подписи;
– окончания срока действия регистрационного свидетельства;
– утери электронного носителя информации с ключевым контейнером, содержащим электронную цифровую подпись;
– наличия повреждений, вызвавших нерабочее состояние электронного носителя информации с ключевым контейнером.
Таким образом, в случае окончания срока действия регистрационного свидетельства необходимо в явочном порядке представить в налоговый орган по месту нахождения налоговое заявление о регистрационном учете электронного налогоплательщика.
§
Ключи импорт ключей взятые с цона, а так же изменение пароля : ис соно система обработки налоговой отчетности
Добрый день всем форумчанам! Хочу поделиться с личным опытом, который возник в процессе импорта новых ключей (с Цона) в налоговую программу СОНО. Срок действия ключа у меня истекал 02.02.2021 года. Решил обновить ключ. Обратился в Налоговое Управление, там сказали мол, сейчас идет обновление, так и сяк, берите ключ с Цона. Соответственно обратился в Цон. Пару дней ожидания, и вот наконец держу в руках флешку с желанными ключами. На вопрос – какой пароль вводить при импорте, сказали – 123456. Уже дома пытаюсь сие действия воспроизвести.
В папке с ключами имеются два вида файлов: 1) AUTH_RSA_3b3626bc7721804e7699bdd5bf4af143dfe5e92f; 2) RSA_417c1f28cce0d99ca9994abf6677dea935e6f454. AUTH_RSA – это для авторизации, а второй ключ, это для подписи.
Делаем следующее:
1) удаляем прежний профиль (профили- профили)
2) создаем новый профиль, указываем все нужные поля (рнн, иин обязателен).Так же указать как физ лицо, так как новые ключи работают как для физ лицо. Ничего страшного в этом нет, ключ будет работать как и для ИП. При импорте ключа в окне появятся три поля. Ключ на УЦ НК указывать не нужно. В остальных полях Ключа НУЦ делаем следующее: в поле «файл с RSA ключом НУЦ для ЭЦП» указываем ключ RSA, а в поле «файл с RSA ключом НУЦ для SSL» – указать ключ AUTH_RSA. Далее вводим к ним пароли. Но в процессе эксплуатации программы почему то просит ключ контейнера УЦ НК. Будем выяснять. На нем просто нажимаем “отмена”, ничего страшного.
Пароли в Цоне могут дать стандартный 123456, но в некоторых областях он 12345678. В моем старом ключе были пароли 111111. Никак не мог привыкнуть к новым, и почему то по необъяснимым причинам выдавали иногда ошибку “Пароль не соответствует” или что-то подобное. Для решения проблемы нужно изменить пароль к данным двум ключам по отдельности. Для этого заходим на портал НУЦ – https://web.pki.kz. Далее заходим в личный кабинет, нажимаем “обновление пароля на ключ”. Отмечаем все заданные поля, а в поле где просят указать путь к файлу ключа выбираем тот файл который вы хотите изменить. Например если хотите изменить пароль к ключу AUTH_RSA, то соответственно выбираем его, если RSA_, то его. А Дальше меняем пароль. Кстати, пароли для двух ключей можно сделать одинаковыми, чтобы не путаться впредь. У меня всё. Спасибо за внимание. Заранее спасибо!
Автор темы еще не зарегистрирован на форуме. Если у Вас есть свободные приглашения на форум, Вы можете выслать приглашение на почтовый адрес: приглашение выслано
У вас нет доступа для скачивания и просмотра вложений, документации, файлов, изображений в этом сообщении. Доступ для зарегистрированных пользователей. Вы можете бесплатно зарегистрироваться на нашем сайте. Если Вы зарегистрированы, то Вам необходимо нажать опцию “Вход” в вверху страницы (там же находится ссылка на страницу регистрации)
Конструктивный форум бухгалтеров казахстана • просмотр темы – переход на «новые ключи нуц» со «старых ключей кн»
На ранних этапах внедрения «новых ключей НУЦ» использовался Тумар. Однако сейчас, уже как несколько лет, он совершенно не нужен. Тумар нужен только для нескольких банков-клиентов.
Ява для работы всех ГВС на текущий момент (август 2021 г.) нужна обязательно. Желательна версия Явы посвежее, однако, как показывает опыт, например, для КН, для входа и подписания, можно использовать и старую версию Явы.
Браузеры для работы с ГВС можно использовать только те, которые поддерживают работу Явы. А таковых становится с течением времени все меньше и меньше. На текущий момент отказались от поддержки Явы (а значит, бесполезны для целей работы с ГВС) следующие браузеры – Мозилла Файрфокс, Яндекс-браузер, Опера, Гугл Хром. Для целей работы с гос-веб-сервисами эти браузеры на текущий момент времени неработоспособны.
Некоторые специалисты рекомендуют для работы с Явой использовать старые версии вышеупомянутых браузеров. Автор статьи категорически не рекомендует так делать. Прежде всего потому, что многие браузеры от любого «неосторожного движения» сами собой могут начать обновляться, и тогда прощай, старая версия. После такого обновления нужно удалить обновившийся (и потому ставший бесполезным) браузер, найти его старую версию, заново установить ее, защитить от случайного обновления, и лишь после этого снова начать работать. Что за ерунда, как будто у пользователя нет других дел и иных, более приемлемых вариантов.
Также, автор не рекомендует использовать для работы с Явой и ГВС так называемые «браузеры для личного общения» – Амиго, Уран, Комета, CoolNovo, и т.д. Просто потому, что эти браузеры предназначены совсем для другого, неделового применения, нашпигованы различной рекламой и прочим ненужным для пользователей ГВС функционалом.
Пока еще остаются в строю следующие браузеры. Это прежде всего Макстон (
http://ru.maxthon.com
), потом 360browser7.5.2.110.exe (так называемый «цветочек», эту версию можно найти в интернете), и наконец, Internet Explorer 8-11 (необходимо настроить совместимость). Впрочем, о браузерах, нужных для работы пользователя ГВС, автор ранее уже писал.
Подготовка подписи к долгосрочному хранению
Проверка подписи под электронным документом включает в себя проверку срока действия сертификата и проверку статуса отозванности сертификата. В том случае, когда необходимо обеспечить юридическую значимость подписанного документа по истечению срока действия сертификата или в том случае, когда сертификат был отозван через некоторое время после подписания, следует собирать дополнительный набор доказательств фиксирующий момент подписания и подтверждающий то, что на момент подписания сертификат не истек и не был отозван.
Для фиксации момента подписания принято использовать метки времени TSP. Метку времени на подпись можно получить либо на клиенте (запрос createCMSSignatureFromBase64 интегрирует метку времени в CMS), либо на сервере. Метка времени позволит удостовериться в том, что момент подписания попадает в срок действия сертификата.
Для того, чтобы удостовериться в том, что сертификат не был отозван в момент подписания, следует использовать CRL или OCSP ответ. Этот нюанс и рекомендации по реализации описаны в разделе APPENDIX B — Placing a Signature At a Particular Point in Time документа RFC 3161.
Поиск информации в xml файлах (xpath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам
XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой
элемент (инструкция <?xmlversion=”1.0”?> к дереву отношения не имеет).
У элемента дерева всегда существуют потомки и предки, кроме корневого
элемента, у которого предков нет, а также тупиковых элементов (листьев
дерева), у которых нет потомков.
Это очень похоже на организацию каталогов в файловой системе, и строки
XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример
списка книг:
XPath запрос /bookstore/book/price вернет следующий результат:
Сокращенная форма этого запроса выглядит так: //price.
С помощью XPath запросов можно искать информацию по атрибутам. Например,
можно найти информацию о книге на итальянском языке: //title[@lang=”it”] вернет <titlelang=”it”>EverydayItalian</title>.
Чтобы получить больше информации, необходимо модифицировать запрос //book[title[@lang=”it”]] вернет:
В приведенной ниже таблице представлены некоторые выражения XPath и
результат их работы:
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная
Что, если я хочу, чтобы мне вернуть только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр —
gender
. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет
FEMALE
, в документации также. Итого получили:
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Проверка подписи на стороне сервера
Тема проверки цифровых подписей обширна и я не планировал раскрывать ее в этот раз, но упомянуть о необходимости выполнения проверок как с технической, так и юридической точки зрения счел необходимым.
С технической точки зрения проверка цифровой подписи на стороне сервера в первую очередь гарантирует целостность полученного документа, во вторую — авторство, а так же неотказуемость. То есть даже в том случае, если ИС получает подписанный документ не напрямую от пользователя, а через какие-то дополнительные слои программного обеспечения, уверенность в том, что было получено именно то, что отправлял пользователь сохраняется.
С юридической точки зрения ориентироваться следует на Приказ Министра по инвестициям и развитию Республики Казахстан “Об утверждении Правил проверки подлинности электронной цифровой подписи”. В Приказе перечислены необходимые проверки которые должны выполнять информационные системы для обеспечения юридической значимости подписанных электронной цифровой подписью документов. Анализу этого документа, а так же некоторым техническим вопросам посвящена заметка Проверка цифровой подписи.
Выполнять проверки необходимо с применением сертифицированных средств, к примеру с помощью библиотек входящих в состав комплекта разработчика НУЦ РК, либо можно воспользоваться готовым решением SIGEX.
Программа “загрузка xml для соно” [для ожидает загрузки xml] : ис соно система обработки налоговой отчетности
После многих просьб, мы всё-таки решили сделать программу, которая исправляет проблемы с отправкой форм 300.00 и форм МОП. У некоторых пользователей отправленные формы встали со статусом:
“Загрузка XML”
и “
Ожидает отправки XML
“.
Мы говорили, что можно подготовить решение, но оно быдет платное.
Сейчас у многих есть три выхода:
- попытаться отключить, удалить антивирус и другие программы, которые мешают отправке отчетности – ВНИМАНИЕ, это опасно, если заразитесь вирусами, или что-то перестанет работать, сами будете виноваты
- отправить бумажно, но формы 300.00 и МОП, как правило большие формы и их отправка или сдача бумажно крайний способ
- рекомендуемый путь: мы разработали программу, которая позволяет отправлять такие формы и без отключения или удаления других программ, через локальные сети, системы защиты и т.д.
По третьему пути: разработанная программа есть результат долгих усилий по разбору проблемы, изучению как СОНО, так и большого количества разных программ.
На ее решение проблемы потрачено много сил, времени и денег, если у Вас нет денег оплатить часть расходов – эта тема не для Вас, Вы можете отключать антивирус, отправлять бумажно и т.д. и т.п. А это программа для тех, кто хочет удобно отправлять любые большие формы.
Разработчики этой программы не являются разработчиками СОНО и потратили много личного времени для того, чтобы решить проблему в комплексе, сделать ее простой, работоспособной и удобной.
Цена программы (обновление информации: программа более платно не распространяется, так что цены на программу удалены):
- —- тенге – эта цена для большинства пользователей, в нее входит программа для отправки формы 300.00 Декларации по НДС, но в нее не входит поддержка форм МОП (это редкие формы) и нет поддержки прокси
- —- тенге – это цена на программу для отправки формы 300.00, но для тех, кто работает через локальную сеть или нужен выход через прокси-сервер. Т.е. у кого компьютер не сам выходит в Интернет, а через локальную сеть, через Ваш локальный сервер, частый вариант в средних и крупных компаниях
- —- тенге – цена на программу с поддержкой формы 300.00, форм МОП по одной из выбранных категорий (Банки, Хоз. субъекты, Страховые компании и т.д.) по выбору
Программа проста в установке (во-много, много раз легче установки СОНО), проверена антивирусами Касперским, NOD32, Симантек (Symantec), Avast, Dr Web и не содержит вирусов.
Версия с поддержкой прокси работает через Kerio Winroute Firewall, Usergate, Wingate и многие другие. Отдельно обсуждается поддержка тех, кто в качестве прокси использует MS ISA или Proxiefier через локальные сети.
Если Вас заинтересовала эта программа, то напишите письмо на адрес:
с темой письма: “Загрузка XML – название организации”
В письме укажите:
*строки, отмеченные звездой обязательно заполните.
Вам вышлют счет на оплату на программу.
Если у Вас прокси сервер или Интернет не прямо к Вам подключен, укажите это также. И какой прокси-сервер используете.
Подсказка “Как быстро узнать есть у Вас прокси или нет”:
Если Ваш браузер Internet Explorer выходит в Интернет (обычно он находится на Рабочем столе в виде синей Буквы e), то откройте эту программу и выполните четко:
* в верхнем меню выберите “Сервис” – “Свойства обозревателя”.
* в новом окне зайдите на “Подключение”
* нажмите кнопочку “Настройка LAN”
* в новом окошке, если стоит галочка на строке “Использовать прокси-сервер для подключения LAN”, значит у Вас используется proxy-сервер, и Вам нужна версия за —- тенге, чтобы программа осуществляла отправку через прокси-сервер Вашей сети.
Ответы на частые вопросы по программе:
- Как будет осуществляться поставка программы?
- Вы высылаете нам данные (наименование организации и т.д.), на их основании выписывается счет на оплату, который высылается Вам на электронную почту
- Вы оплачивайте счет
- после оплаты счета, Вы получаете программу и инструкции, рекомендации, помощь по ней
- после того, как программа у Вас заработает, мы выставим Акт на программу, вы его подпишите и вышлите два экземпляра подписанных нам на почту
- на основании акта Вам будут выслана налоговая счет-фактура и один экземпляр подписанного с двух сторон Акта на программу
- это программа только для 1 и 2 квартала 2009 года?
Нет, эта программа на всё время пока будет актуальна проблема с “Ожидает загрузки XML” - не будет ли мешать это отчетам, которые уже отправлены?
нет, не будет, она поможет отправить те, что уже стоят со статусом “Ожидает загрузки XML” или “Загрузка XML”, а также все последующие формы 300.00 и формы МОП
P.S. можете ругать или нет, но здесь эта программа для решения проблемы
Ожидает загрузки XML
доступна к заказу по просьбе пользователей. Если Вы не можете себе это позволить, то удаляйте антивирус, отключайте, посылайте почтой и т.д. Это только альтернатива и помощь тем, кто не может найти другого решения, а отключать антивирус это достаточно опасно (работа без антивируса может угрожать безопасности Ваших данных), а бумажно посылать некрасиво
P.P.S. обновление информации: программа более платно не распространяется, так что цены на программу удалены, получить программу могут только самые активные участники форума, кто помогает другим, развивает форум, участвует в Клубе и т.д., более программа платно не распространяется
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите,
например, символ < внутри XML элемента, то будет
сгенерирована ошибка, так как парсер интерпретирует его, как начало
нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении “ООО<Мосавтогруз>” атрибута НаимОрг содержатся символы < и >.
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
Чтобы ошибки не возникали, нужно заменить символ < на его
сущность. В XML существует 5 предопределенных сущностей:
Таким образом, корректными будут следующие формы записей:
или
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Указанный вами ключ поврежден или не соответствует требуемому алгоритму шифрования для юл
Ошибка возникает при попытке подключить ключ ЭЦП Индивидуального предпринимателя (ИП) или Физического лица (ФЛ) в профиль СОНО.
Для исправления проблемы, укажите правильный Тип налогоплательщика в в верхней части окна профиля СОНО.
Шаг 2. установка соно и настройка сертификатов соно.
Когда мы скачали все необходимые нам файлы, первым запускаем файл BaseSetupTR.exe. Устанавливаем все по умолчанию. Далее запускаем файл Setup_np_tr.exe. При установке со всем соглашаемся и также все ставим по умолчанию. (Для установки программы необходимо иметь права администратора на компьютере)
Запускаем с рабочего стола СОНО НП и создаем новый профиль.
Новый профиль СОНО
Даем ему любое имя (лучше всего название Вашей компании или ИП). Далее заполняем как можно больше полей (минимум нужно заполнить ИИН/БИН и название организации).
Новый профиль СОНО
На следующей форме указываем ключ(и). Если у Вас налоговый ключ (1 файл), то указываем его с левой стороны формы, если у Вас двойной ключ вида RSA* и GOST*, то указываем их оба с правой стороны формы заполнения.
Указываем сертификаты для СОНО
В данном примере у нас ключи из ЦОНа.
Установка ключей СОНО
Жмем кнопку «Завершить». Профиль настроен, осталось импортировать необходимые формы.
Шаг 3. загрузка шаблонов фно в соно нп.
Примечание: Загрузка шаблонов может производиться в любое время после установки программы, а также по мере необходимости установки новых форм
Закройте СОНО. Через поиск «Windows» находим программу «загрузка шаблонов ФНО» запускаем ее. (В Windows 7 загрузку шаблонов ФНО легче найти через кнопку «ПУСК-Программы-SONO-Загрузка шаблонов ФНО«)
Загрузка шаблонов ФНО
Запускаем, нажимаем кнопку многоточие, указываем путь и через зажатую кнопку CTRL на клавиатуре указываем все необходимые формы.
Загрузка шаблонов ФНО
Ждем, когда выйдет сообщение «Загрузка форм завершена». Закрываем программу, запускаем СОНО.
Можно приступать к работе.
Если в статье осталось что-то непонятным, Вы можете ознакомиться с видеоверсией данной статьи на практическом примере
Источник
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.
Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XMLУчебник по XMLИзучаем XML. Эрик Рэй (книга по XML) Заметки о XML и XLST
Что такое JSON — второй популярный формат







